
Table of Contents
概览
本文是对个人项目 microservices-go-zero的详细介绍。
microservices-go-zero基于go-zero的民宿微服务系统,包括用户中心服务、民宿服务、订单服务和支付服务。
系统架构
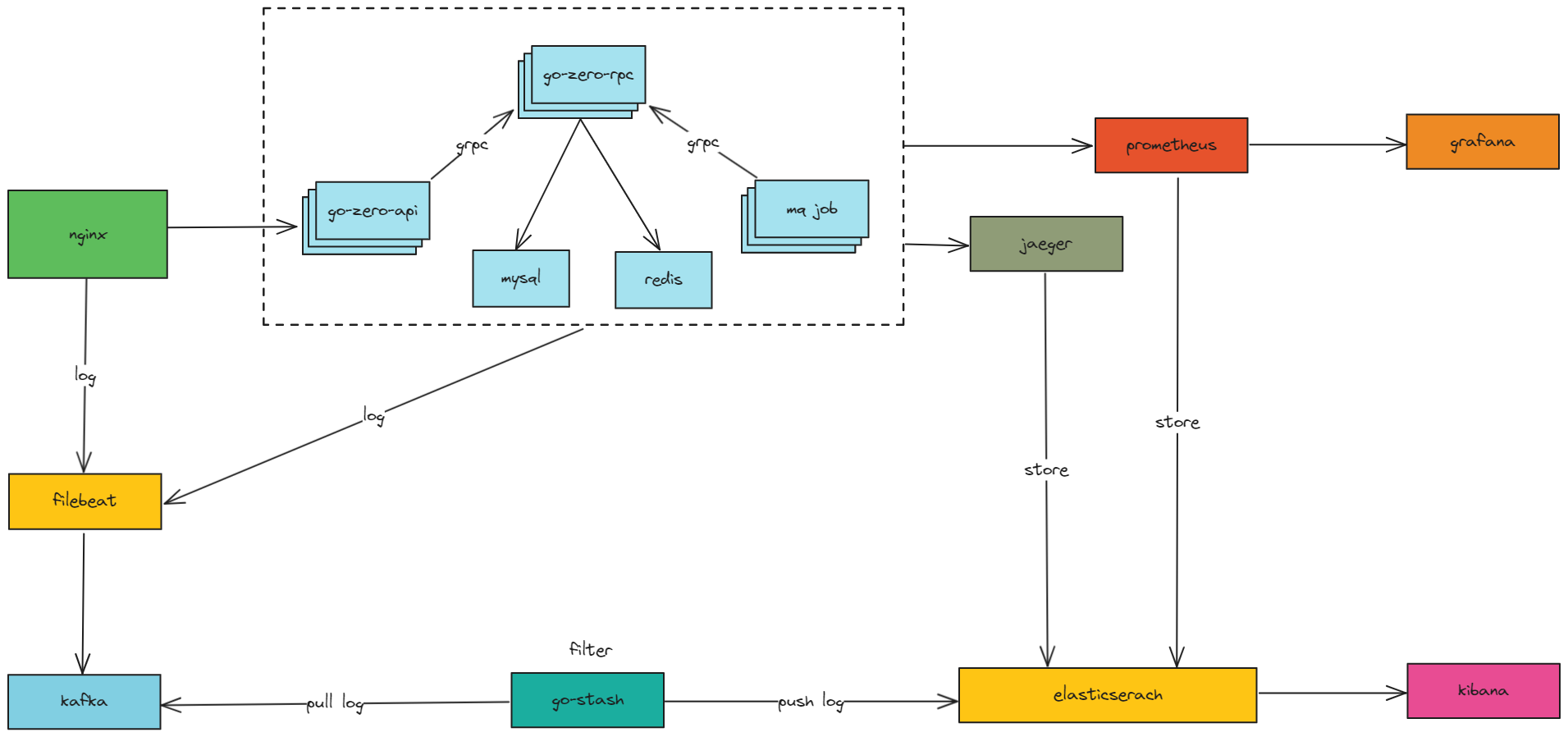
业务架构
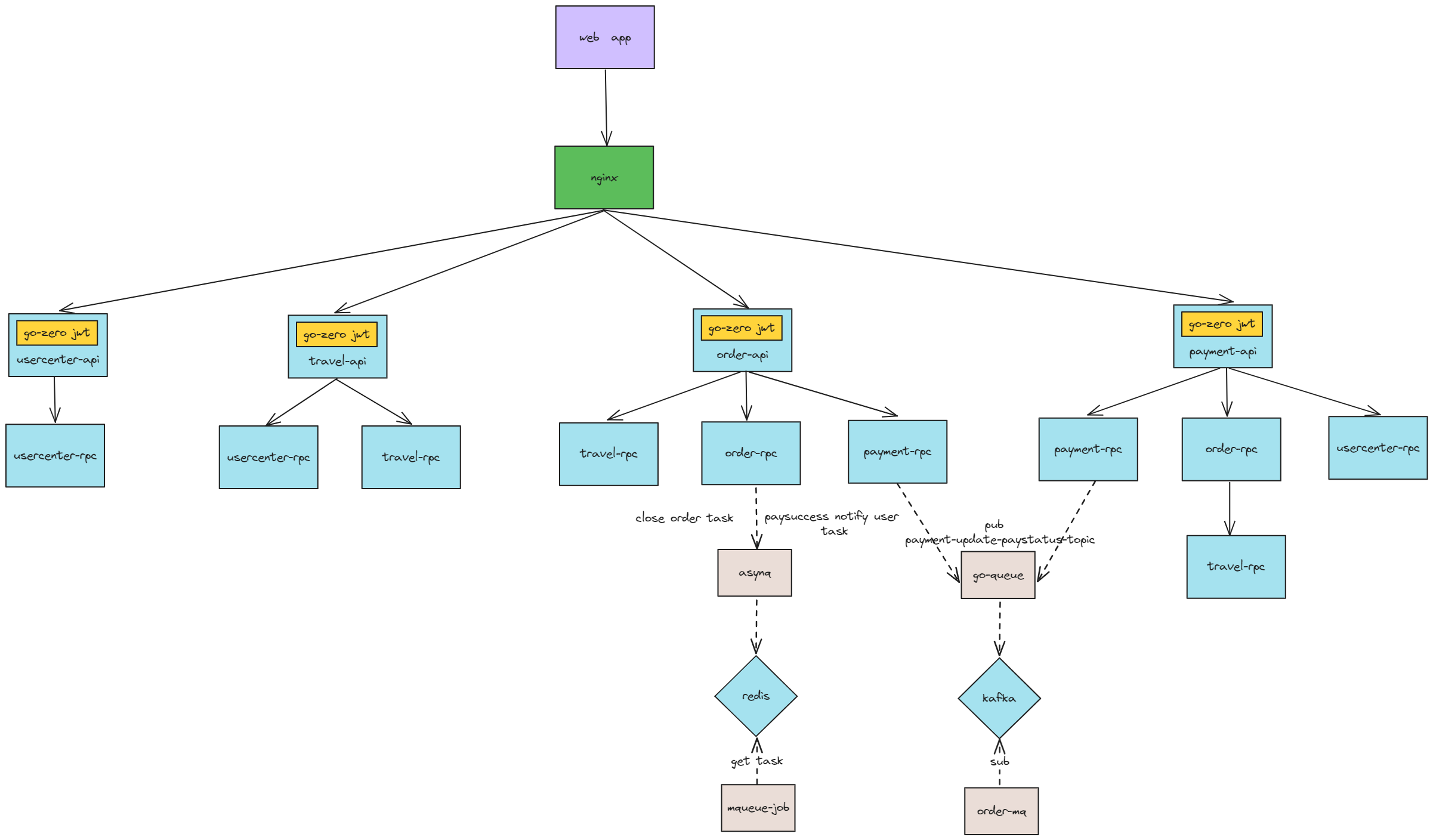
Feature
-
使用
go-zero框架进行开发,稳定、高性能。 -
使用
Nginx作为对外网关,前面可接入SLB负载均衡器,并配合go-zero-jwt进行认证。 -
采用微服务开发模式,结合
API (HTTP)和RPC (gRPC)。API充当聚合服务,将复杂、涉及其他业务调用的逻辑统一放在RPC中。项目使用直链方式,放弃服务注册发现中间件带来的麻烦。 -
使用
go-queue实现订单支付状态更新消息队列,asynq实现支付成功通知用户消息队列和关闭超时未支付订单延时队列。 -
使用
Filebeat统一收集系统日志(各组件和业务),采集和转发日志数据到Kafka。使用Go-Stash替代Logstash进行日志过滤,高性能且资源消耗较低。使用Prometheus进行系统性能监控。使用Jaeger进行链路追踪,帮助微服务架构的监控和故障排查。Elasticsearch存储系统日志数据、监控数据和链路追踪数据,并进行数据分析。 -
数据库使用
mysql,并使用redis作为缓存、消息队列和延时队列。
Docker Compose部署项目
docker-compose-env.yaml解读
项目所有组件如监控、日志、消息队列、数据库以及核心业务逻辑都通过docker部署,并通过docker network进行通信和隔离。
docker network
直接通过
yaml文件启动时会自动创建目标docker network。
使用docker network create命令在Docker中创建一个网络,默认将创建bridge类型的网络。此外还可以添加显式添加--driver选项支持host、container等其他网络类型。创建网络后,可以使用以下命令列出所有Docker网络,以验证网络是否已成功创建:
docker network ls创建网络后,你可以在运行容器时通过--network选项将容器连接到这个网络。例如:
docker run --name some-app --network microservices_net -d some-image创建Docker网络主要用于容器间的隔离和通信。Docker自身提供了简单的内置DNS服务,用于容器名到IP地址的解析,这使得可以更容易地通过容器名称进行互联,而不是通过IP地址,
Docker容器每次重启后容器ip是会发生变化的。这也意味着如果容器间使用ip地址来进行通信的话,一旦有容器重启,重启的容器将不再能被访问到。
docker-compose-env.yaml
使用docker-compose部署项目依赖环境。
服务组件:
Jaeger- 用于链路追踪,帮助监控和故障排查微服务架构的性能问题。Prometheus- 监控工具,收集和存储指标数据,用于系统的性能监控。Grafana- 与Prometheus配合使用,提供数据可视化界面,用于展示监控数据。Elasticsearch- 高效的搜索和数据分析引擎,这里用于存储日志和监控数据。Kibana-Elasticsearch的数据可视化前端工具,用于查看和分析在Elasticsearch中的数据。Go-Stash- 日志处理服务,用于处理和转发日志数据到Elasticsearch。Filebeat- 轻量级日志收集器,用于采集和转发日志数据到Kafka。Zookeeper- 分布式服务的协调工具,Kafka的依赖服务。Kafka- 高吞吐量的分布式消息队列,用于日志和事件的传输。Asynqmon- 提供Web UI管理Asynq任务队列和监控。MySQL- 关系型数据库,用于存储应用数据。Redis- 内存中的kv键值数据库,用作数据库、缓存和消息代理。
网络配置:
microservices_net:所有服务都连接到这个自定义bridge网络,允许容器间通信和隔离外部网络。网络配置指定了子网为172.16.0.0/16,确保容器间网络通信不受外界干扰。
Docker将为172.16.0.0/16网络创建一个新的虚拟桥接,并负责为连接到同一网络的容器自动分配IP地址。虽然容器内部使用的是隔离的子网,但它们可以通过NAT(网络地址转换)访问外部网络。宿主机可以通过端口映射访问运行在容器内的服务,例如,将容器的80端口映射到宿主机的8080端口,从而从宿主机网络访问容器服务。
其他配置:
Volumes:多个服务使用卷(volumes)来持久化和共享数据。例如,Prometheus、Grafana、Elasticsearch等服务的数据都被保存在本地文件系统中,以便在容器重启后数据不会丢失。Ports:服务如Prometheus、Grafana、Kibana等对外暴露端口,使得可以从宿主机器访问这些服务。Environment:设置环境变量,如时区设置为上海(Asia/Shanghai),以及其他服务特定的配置。
Docker Compose默认会给每个网络前缀一个项目名称,通常是目录名。项目目录名是microservices-go-zero,那么实际的网络名自动变成了microservices-go-zero_microservices_net
docker-compose.yaml解读
nginx:创建一个前端网关,主要负责代理microservices服务,但不代理admin-api服务。gomodd:提供golang环境运行具体代码逻辑以及modd的热加载功能,修改代码即时生效,无需重启容器服务。
gomodd
使用modd热加载代码,modd监控文件修改并重启服务进程,修改代码即生效,无需手动重新编译并运行。
我们在docker-compose.yaml文件中的microservices部分将项目根目录挂载至microservices容器的/go/microservices路径,modd会自动在工作目录寻找modd.conf文件并进行应用。
prep命令在执行后终止(例如编译、运行测试套件或运行linters),只要对应文件块被修改,prep命令会被自动触发。daemon命令在启动后持续运行(例如数据库或网络服务器)。当触发它们所在的块时,默认情况下,守护进程会接收到一个SIGHUP信号,并且如果它们退出了,就会重启。
在
Linux系统中,kill -SIGHUP是发送SIGHUP信号给进程的命令。SIGHUP是一种用于通知进程重新读取配置文件或重新加载的信号,通常用于重新启动服务或重新加载配置。当进程收到SIGHUP信号时,它会尝试重新读取其配置文件或重新加载,以使最新的配置生效。这使得管理员可以在不中断服务的情况下更改配置。
prep命令按照编写的顺序运行。如果任何prep命令以错误退出,当前块的执行立即停止。如果所有prep命令成功了,块中的任何守护进程也会按照出现的顺序重启。如果同一组更改触发了多个块,它们也会按照从上到下的顺序运行。
所有服务编译至/data/server路径。
使用docker compose创建项目所依赖环境
docker-compose -f docker-compose-env.yaml up -d
docker-compose创建完成后,使用docker ps查看是否所有容器都处于up状态。如果有一直restarting的容器,需要使用docker logs 容器名进行排查并重启。
创建kafka topic
主题(Topics)是消息的分类或者说是消息的目的地。每个消息发布到一个特定的主题中,而消费者可以订阅一个或多个主题来接收消息。创建两个Kafka主题:microservices-log和payment-update-paystatus-topic,分别用于日志收集和支付成功后通知所有订阅者。
docker exec -it kafka /bin/shcd /opt/kafka/bin/./kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 -partitions 1 --topic microservices-log./kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 -partitions 1 --topic payment-update-paystatus-topic--create: 指示脚本创建一个新主题。--zookeeper: 指定Zookeeper的地址和端口,Kafka使用Zookeeper来维护集群状态。--replication-factor: 设置复制因子,为1意味着每个消息在Kafka集群中只有一个副本。--partitions: 设置分区数为,分区是Kafka的横向扩展机制,但在这里只需要一个分区。--topic: 指定主题名称。
导入MySql数据
为root设置远程连接权限,以便使用navicat操作。
docker exec -it mysql mysql -uroot -p##输入密码:PXDN93VRKUm8TeE7use mysql;update user set host='%' where user='root';FLUSH PRIVILEGES;使用navicat创建数据库并导入数据(创建数据库后,进入数据库并运行对应sql文件):
- 创建数据库
microservices_order,导入deploy/sql/microservices_order.sql数据。 - 创建数据库
microservices_payment,导入deploy/sql/microservices_payment.sql数据。 - 创建数据库
microservices_travel,导入deploy/sql/microservices_travel.sql数据。 - 创建数据库
microservices_usercenter,导入microservices_usercenter.sql数据。
数据库字符集选择
utf8mb4;排序规则选择utf8mb4_general_ci。
启动项目
docker-compose up -d
docker-compose创建完成后,使用docker ps查看是否所有容器都处于up状态。如果有一直restarting的容器,需要使用docker logs 容器名进行排查并重启。
查看项目运行情况
访问http://127.0.0.1:9090/,点击菜单Status/Targets,蓝色表示启动成功,红色表示启动失败。
项目第一次构建会拉取依赖,所有服务启动成功可能需要一段时间。
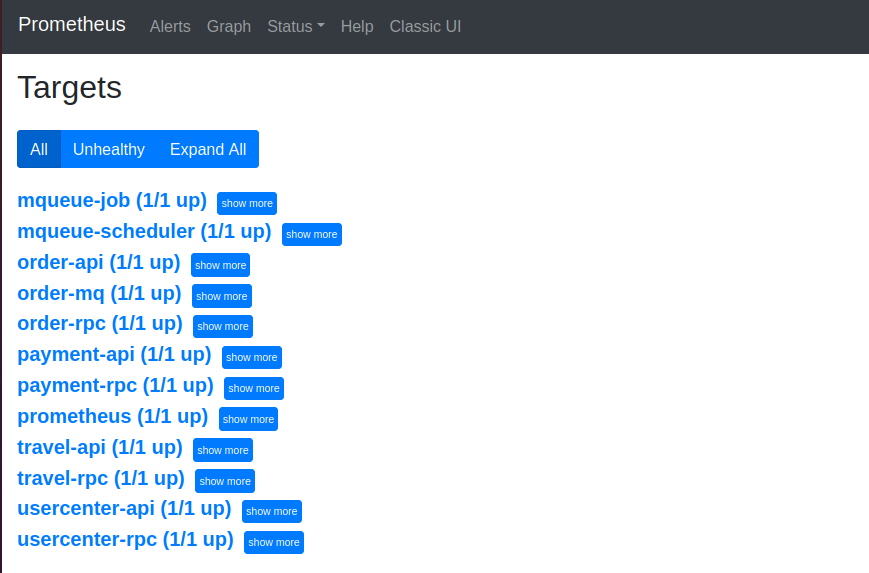
服务端口
Service
| service name | api service port(1xxx) | rpc service port(2xxx) | other service port(3xxx) |
|---|---|---|---|
| order | 1001 | 2001 | mq-3001 |
| payment | 1002 | 2002 | |
| travel | 1003 | 2003 | |
| usercenter | 1004 | 2004 | |
| mqueue | - | - | job-3002、schedule-3003 |
Prometheus
| service name | prometheus port |
|---|---|
| order-api | 4001 |
| order-rpc | 4002 |
| order-mq | 4003 |
| payment-api | 4004 |
| payment-rpc | 4005 |
| travel-api | 4006 |
| travel-rpc | 4007 |
| usercenter-api | 4008 |
| usercenter-rpc | 4009 |
| mqueue-job | 4010 |
| mqueue-scheduler | 4011 |
访问项目
项目使用nginx作为网关,nginx对外暴露端口为8888,通过8888端口可访问api(api内部通信为rpc)提供服务:
curl -X POST "http://127.0.0.1:8888/usercenter/v1/user/register" -H "Content-Type: application/json" -d "{\"mobile\":\"18888888888\",\"password\":\"123456\"}"服务访问成功将返回code:200,同时在microservices_usercenter数据库中能存在注册的用户条目。
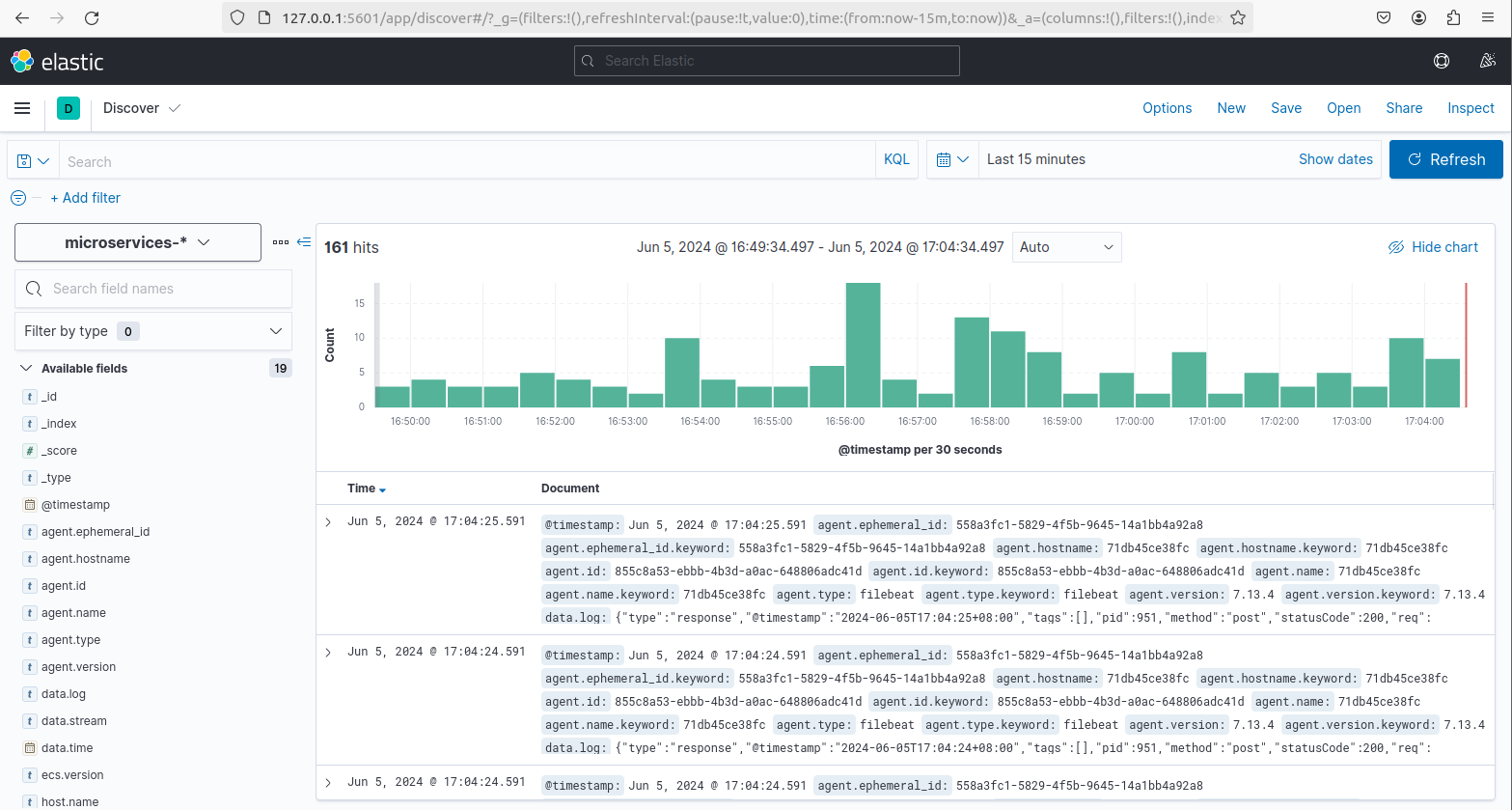
日志收集
项目日志收集流程如下:
filebeat收集日志 -> kafka -> go-stash消费kafka日志 -> 输出到es中 -> kibana查看es数据收集日志,需要创建日志索引:
- 访问
kibana:http://127.0.0.1:5601/, 创建日志索引 - 点击左上角菜单,选择
Analytics/discover - 选择
Create index pattern,输入microservices-*,点击Next Step,选择@timestamp->Create index pattern - 点击左上角菜单,选择
Analytics/discover,日志显示
项目启动常见问题
filebeat
Exiting: error loading config file: config file ("filebeat.yml") must be owned by the user identifier (uid=0) or root解决办法:
sudo chown root deploy/filebeat/conf/filebeat.ymlelasticserach
ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes];Likely root cause: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes解决办法:
sudo chmod 777 data/elasticsearch/dataGo-Zero
go-zero是一个集成了各种工程实践的 web 和 rpc 框架。通过弹性设计保障了大并发服务端的稳定性,经受了充分的实战检验。本项目使用go-zero框架结合各种常用中间件构建微服务系统架构。
goctl
goctl是go-zero配套的代码生成工具脚手架,其集成了Go HTTP服务,Go gRPC服务,数据库model,k8s,Dockerfile等生成功能。
如果go版本在1.16以前,则使用如下命令安装:
GO111MODULE=on go get -u github.com/zeromicro/go-zero/tools/goctl@latest如果go版本在1.16及以后,则使用如下命令安装:
go install github.com/zeromicro/go-zero/tools/goctl@latest验证安装:
goctl --version如果安装完成却显示不出版本,则需要检查是否将
$GOPATH/bin加入至环境变量中。
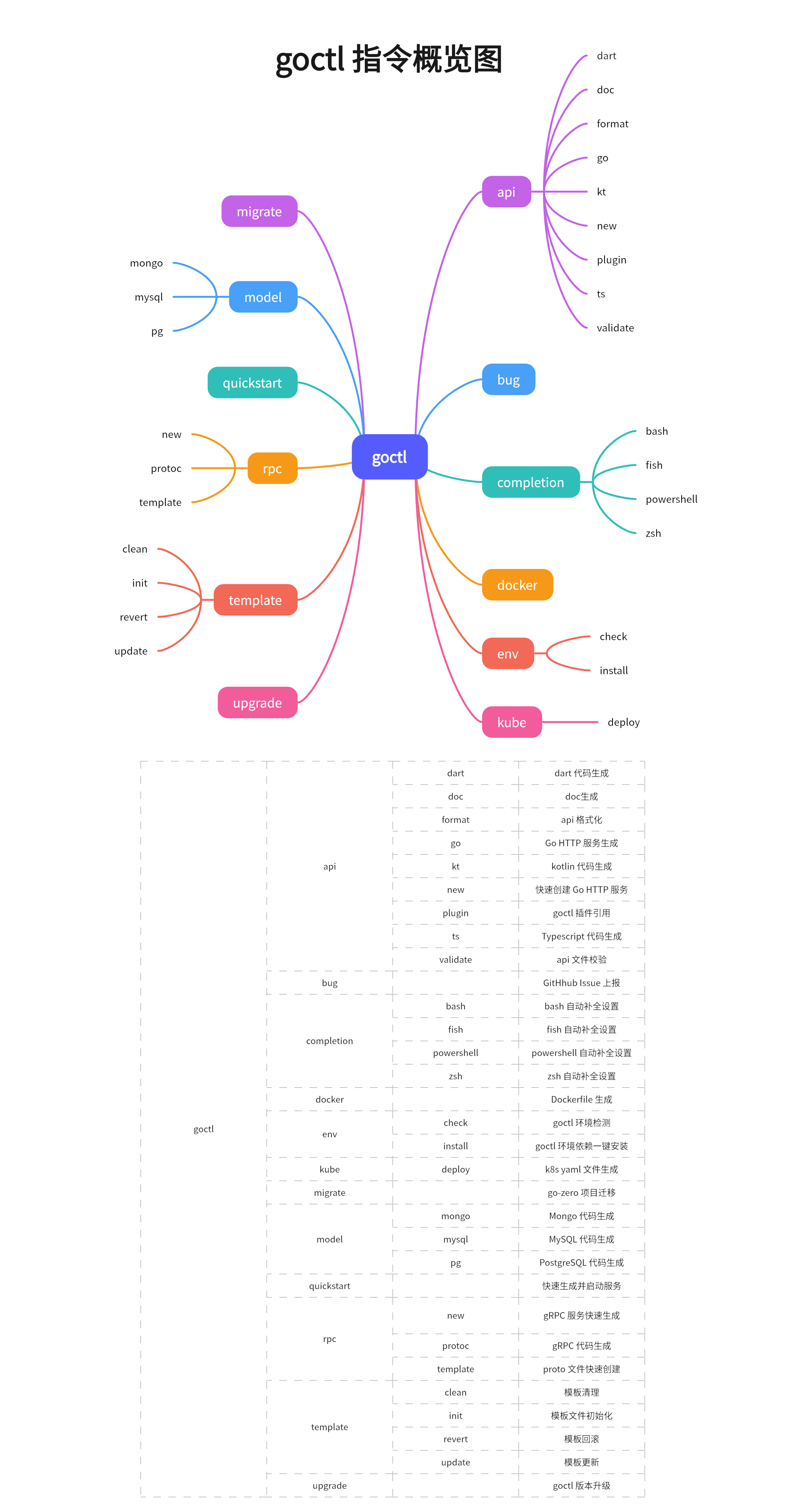
使用go-zero构建微服务
编写api文件,生成基本的api代码
- 语法
- goctl api生成代码
api文件只需写明具体的路由、HTTP方法、请求体和响应体
编写proto文件,生成基本的rpc代码
- 语法
- goctl rpc生成代码
proto需要写明消息和rpc调用方法
根据sql文件或数据库连接,生成数据库model代码
可通过两种方式生成model代码,均通过goctl model生成:
sql文件- 数据库连接
在生成model代码时,加上-c参数即可生成集成redis缓存的框架代码。缓存默认过期时间是7天,查不到数据会为其设置一个空缓存,默认过期时间为1分钟(避免缓存穿透),此外go-zero缓存和数据库一致性采用旁路模型,当删除或更新数据时,会先更新数据库,再删除对应的行缓存记录。
生成的model代码提供了基础的针对主键和唯一键的数据库(sql)操作,更多复杂的crud需要在对应的*_gen.go中编写并在接口中注册。此外,go-zero的数据库事务操作只能在对应的model中进行调用,但我们可以对其进行暴露,使得可以在编写具体的HTTP/RPC逻辑时调用。
示例:
type userModel interface { // TransactCtx can only be applied locally, so it is encapsulated, registered and exposed Trans(ctx context.Context, fn func(context context.Context, session sqlx.Session) error) error}
func (m *defaultUserModel) Trans(ctx context.Context, fn func(ctx context.Context, session sqlx.Session) error) error { return m.TransactCtx(ctx, func(ctx context.Context, session sqlx.Session) error { return fn(ctx, session) })}
// 调用示例UserModel.Trans(ctx, func(ctx context.Context, session sqlx.Session) error { // 具体的逻辑 return nil}补充rpc服务逻辑
- 根据需要修改
rpc代码的配置文件rpc/etc/*.yaml,例如修改监听的地址和端口,或者增加数据库、cache、log、redis、监控和链路追踪等配置。 - 在
rpc/internal/config/config.go中为config结构体增加对应的配置字段,rpc服务在启动后会将yaml文件中的内容解析至config中。 - 在
rpc/internal/svc/serviceContext.go中为ServiceContext结构体增加对应的配置字段,例如redis和数据库实例,并在NewServiceContext中完成资源和组件的初始化。 - 在
rpc/internal/logic中编写具体调用方法的逻辑。
rpc服务主程序示例:
var configFile = flag.String("f", "etc/usercenter.yaml", "the config file")
func main() { flag.Parse()
var c config.Config conf.MustLoad(*configFile, &c) ctx := svc.NewServiceContext(c)
s := zrpc.MustNewServer(c.RpcServerConf, func(grpcServer *grpc.Server) { pb.RegisterUsercenterServer(grpcServer, server.NewUsercenterServer(ctx))
if c.Mode == service.DevMode || c.Mode == service.TestMode { reflection.Register(grpcServer) } }) defer s.Stop()
fmt.Printf("Starting rpc server at %s...\n", c.ListenOn) s.Start()}主要流程:
- 解析配置文件到
config.Config中 - 根据
config.Config初始化组件和资源 - 创建新的
gRPC服务器实例,服务器会从配置结构config.Config.RpcServerConf中读取具体的服务器配置 - 将具体的服务逻辑注册到
gRPC服务器中,使得服务器能够知道如何处理特定的rpc调用
补充HTTP服务逻辑
- 根据需要修改
rpc代码的配置文件api/etc/*.yaml,例如修改监听的地址和端口,或者增加rpc、log、监控和链路追踪等配置。 - 在
api/internal/config/config.go中为config结构体增加对应的配置字段,api服务在启动后会将yaml文件中的内容解析至config中。 - 在
api/internal/svc/serviceContext.go中为ServiceContext结构体增加对应的配置字段,例如rpc实例,并在NewServiceContext中完成资源和组件的初始化。 - 在
api/internal/logic中编写具体调用方法的逻辑。
HTTP服务主程序示例:
var configFile = flag.String("f", "etc/usercenter.yaml", "the config file")
func main() { flag.Parse()
var c config.Config conf.MustLoad(*configFile, &c)
server := rest.MustNewServer(c.RestConf) defer server.Stop()
ctx := svc.NewServiceContext(c) handler.RegisterHandlers(server, ctx)
fmt.Printf("Starting server at %s:%d...\n", c.Host, c.Port) server.Start()}主要流程:
- 解析配置文件到
config.Config中 - 创建新的
HTTP服务器实例,服务器会从配置结构config.Config.RestConf中读取具体的服务器配置 - 根据
config.Config初始化组件和资源 - 注册所有的路由和对应的
handler到服务器 - 服务器启动并监听
http请求,当服务器收到具体的http请求时,调用具体的handler函数,handler函数将解析请求体,调用具体的逻辑方法,并构造请求体返回
Nginx
项目使用nginx做为网关,用于将不同的请求路径转发到不同的微服务。
我们在docker-compose.yaml文件中的nginx-gateway部分将该配置文件挂载至nginx-gateway容器的/etc/nginx/conf.d/microservices-gateway.conf路径进行应用,并将/var/log/nginx路径下的日志持久化到/data/nginx/log目录,并将该容器8081端口映射至主机的8888端口。
listen 8081; access_log /var/log/nginx/microservices.com_access.log; error_log /var/log/nginx/microservices.com_error.log;Nginx监听的端口号为8081(也就是主机的8888端口),所有发往这个端口的HTTP请求都将由这个服务器处理。
access_log,/var/log/nginx/microservices.com_access.log:记录所有接入请求的详细信息。error_log,/var/log/nginx/microservices.com_error.log:记录所有错误信息。
每个location块定义了不同的请求路径,并指定了如何处理这些路径的请求。
设置传递给代理服务器(nginx服务)的请求头,这些头包括:
Host $http_host; 传递原始请求的主机头。X-Real-IP $remote_addr; 传递请求者的IP地址。REMOTE-HOST $remote_addr; 同上,通常用于日志或其他用途。X-Forwarded-For $proxy_add_x_forwarded_for; 添加代理服务器的IP地址到X-Forwarded-For头,用于跟踪请求链。
指定请求应该被转发到的目标地址和端口:
/order/:请求被转发到http://microservices:1001/payment/:请求被转发到http://microservices:1002/travel/:请求被转发到http://microservices:1003/usercenter/:请求被转发到http://microservices:1004
JWT
JWT介绍
本项目使用go-zero-jwt进行服务认证。JSON Web Token(缩写 JWT)是目前最流行的跨域认证解决方案,拥有以下特点:
JWT默认是不加密,但也是可以加密的。生成原始Token以后,可以用密钥再加密一次。JWT不加密的情况下,不能将秘密数据写入JWT。JWT不仅可以用于认证,也可以用于交换信息。有效使用JWT,可以降低服务器查询数据库的次数。JWT的最大缺点是,由于服务器不保存session状态,因此无法在使用过程中废止某个token,或者更改token的权限。也就是说,一旦JWT签发了,在到期之前就会始终有效,除非服务器部署额外的逻辑。JWT本身包含了认证信息,一旦泄露,任何人都可以获得该令牌的所有权限。为了减少盗用,JWT的有效期应该设置得比较短。对于一些比较重要的权限,使用时应该再次对用户进行认证。- 为了减少盗用,
JWT不应该使用HTTP协议明码传输,要使用HTTPS协议传输。
JWT 的原理是,服务器认证以后,生成一个 JSON 对象,发回给用户,就像下面这样。
{ "姓名": "张三", "角色": "管理员", "到期时间": "2018年7月1日0点0分"}以后,用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份。服务器就不保存任何 session 数据了,也就是说,服务器变成无状态了,从而比较容易实现扩展。为了防止用户篡改数据,服务器在生成这个对象的时候,会加上签名。实际的 JWT 大概就像下面这样。

它是一个很长的字符串,中间用点(.)分隔成三个部分。JWT 的三个部分依次如下:
Header(头部)Payload(负载)Signature(签名)
注意,JWT 内部是没有换行的,写成一行,就是Header.Payload.Signature的形式。
Header:Header 部分是一个 JSON 对象,描述 JWT 的元数据,通常是下面的样子。
{ "alg": "HS256", "typ": "JWT"}上面代码中,alg属性表示签名的算法(algorithm),默认是 HMAC SHA256(写成 HS256);typ属性表示这个令牌(token)的类型(type),JWT 令牌统一写为JWT。最后,将上面的 JSON 对象使用 Base64URL 算法转成字符串。
Payload:Payload 部分也是一个 JSON 对象,用来存放实际需要传递的数据。JWT 规定了7个官方字段,供选用。
iss(issuer):签发人exp(expiration time):过期时间sub(subject):主题aud(audience):受众nbf(Not Before):生效时间iat(Issued At):签发时间jti(JWT ID):编号
除了官方字段,你还可以在这个部分定义私有字段,下面就是一个例子。
{"sub": "1234567890","name": "John Doe","admin": true}注意,JWT 默认是不加密的,任何人都可以读到,所以不要把秘密信息放在这个部分。这个 JSON 对象也要使用 Base64URL 算法转成字符串。
Signature:Signature 部分是对前两部分的签名,防止数据篡改。
首先,需要指定一个密钥(secret)。这个密钥只有服务器才知道,不能泄露给用户。然后,使用 Header 里面指定的签名算法(默认是 HMAC SHA256),按照下面的公式产生签名。
HMACSHA256(base64UrlEncode(header) + "." +base64UrlEncode(payload),secret)算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用”点”(.)分隔,就可以返回给用户。
Base64URL
前面提到,Header 和 Payload 串型化的算法是 Base64URL。这个算法跟 Base64 算法基本类似,但有一些小的不同。JWT 作为一个令牌(token),有些场合可能会放到 URL(比如 api.example.com/?token=xxx)。Base64 有三个字符+、/和=,在 URL 里面有特殊含义,所以要被替换掉:=被省略、+替换成-,/替换成_ 。这就是 Base64URL 算法。
使用方式
客户端收到服务器返回的 JWT,可以储存在 Cookie 里面,也可以储存在 localStorage。此后,客户端每次与服务器通信,都要带上这个 JWT。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP 请求的头信息Authorization字段里面,本项目使用这种方法。
Authorization: Bearer <token>另一种做法是,跨域的时候,JWT 就放在 POST 请求的数据体里面。
go-zero-jwt
使用go-zero-jwt十分简单,只需要在编写api文件时通过在 @server 中来通过 jwt 关键字声明了开启 jwt 认证,且该 jwt 认证仅对其对应的路由有用,如上面的 jwt 仅对 /user/info 生效,我们使用 Auth 来作为 jwt 的值,其在经过 goctl 进行代码生成后会转成 对应 jwt 配置。
@server ( jwt: Auth // 开启 jwt 认证)service user-api { @handler userInfo post /user/info (UserInfoReq) returns (UserInfoResp)}生成的jwt代码如下:
package config
import "github.com/zeromicro/go-zero/rest"
type Config struct { rest.RestConf Auth struct {// JWT 认证需要的密钥和过期时间配置 AccessSecret string AccessExpire int64 }}
// routes.gofunc RegisterHandlers(server *rest.Server, serverCtx *svc.ServiceContext) { server.AddRoutes( []rest.Route{ { Method: http.MethodPost, Path: "/user/info", Handler: userInfoHandler(serverCtx), }, }, rest.WithJwt(serverCtx.Config.Auth.AccessSecret), )}jwt 通常可以携带一些自定义信息,本项目中server端生成 jwt key 时添加了 jwtUserId 值,go-zero 在解析后会将所有载体放到 context 中,并通过context.Value获取载体信息。
消息队列
kafka
Apache Kafka是一个开源的分布式事件流平台,用于构建实时数据管道和流式应用程序。它被设计用于处理高吞吐量、容错性强和可扩展的数据流。
Kafka的主要特点包括:
-
发布-订阅消息系统:
Kafka遵循发布-订阅模型,生产者将消息发布到主题,消费者订阅这些主题以接收消息。 -
可扩展性:
Kafka可水平扩展,通过添加更多的代理到Kafka集群来轻松扩展规模。 -
容错性:
Kafka在多个代理之间复制数据以确保容错性。如果一个代理失败,数据仍可以从其他代理上的复制数据中检索。 -
高吞吐量:
Kafka能够处理每秒大量的消息,适用于需要实时数据处理的用例。 -
数据保留:
Kafka会保留消息一段可配置的时间,允许消费者检索历史数据。 -
流处理:
Kafka Streams API支持对存储在Kafka主题中的数据进行实时流处理和分析。 -
连接器:
Kafka Connect允许与外部系统轻松集成,将数据导入/导出到Kafka中。
本项目中filebeat收集日志后,将消息发送至kafka中,再由go-stash消费kafka日志,最后输出到es中。此外,使用go-queue-kq基于kafka实现订单支付状态更新的消息队列。
go-queue
go-queue是go-zero官方提供的消息队列组件,可分为kq和dq:
kq是基于kafka Pub & Sub框架的消息队列dq是基于beanstalkd的延迟队列
项目使用go-queue-kq实现根据第三方支付订单支付状态更新修改订单支付状态的消息队列。order-mq为消费者的实现,从kafka特定topic中取出第三方支付消息进行消费,并修改订单支付状态。payment中实现了生产者(pusher),将第三方支付消息推送至kafka特定topic中。
go-queue不支持定时队列。
asynq
Asynq是一个Google提供的Go库,用于对任务进行排队并使用工作程序异步处理任务。Asynq直接基于Redis,可扩展且易于上手。前期如果业务量不大时可以直接使用Asynq,节省一个中间件。项目使用了asynq实取消超时未支付订单的延时队列和订阅消息通知用户订单状态更新的消息队列,以及定时队列的示例。
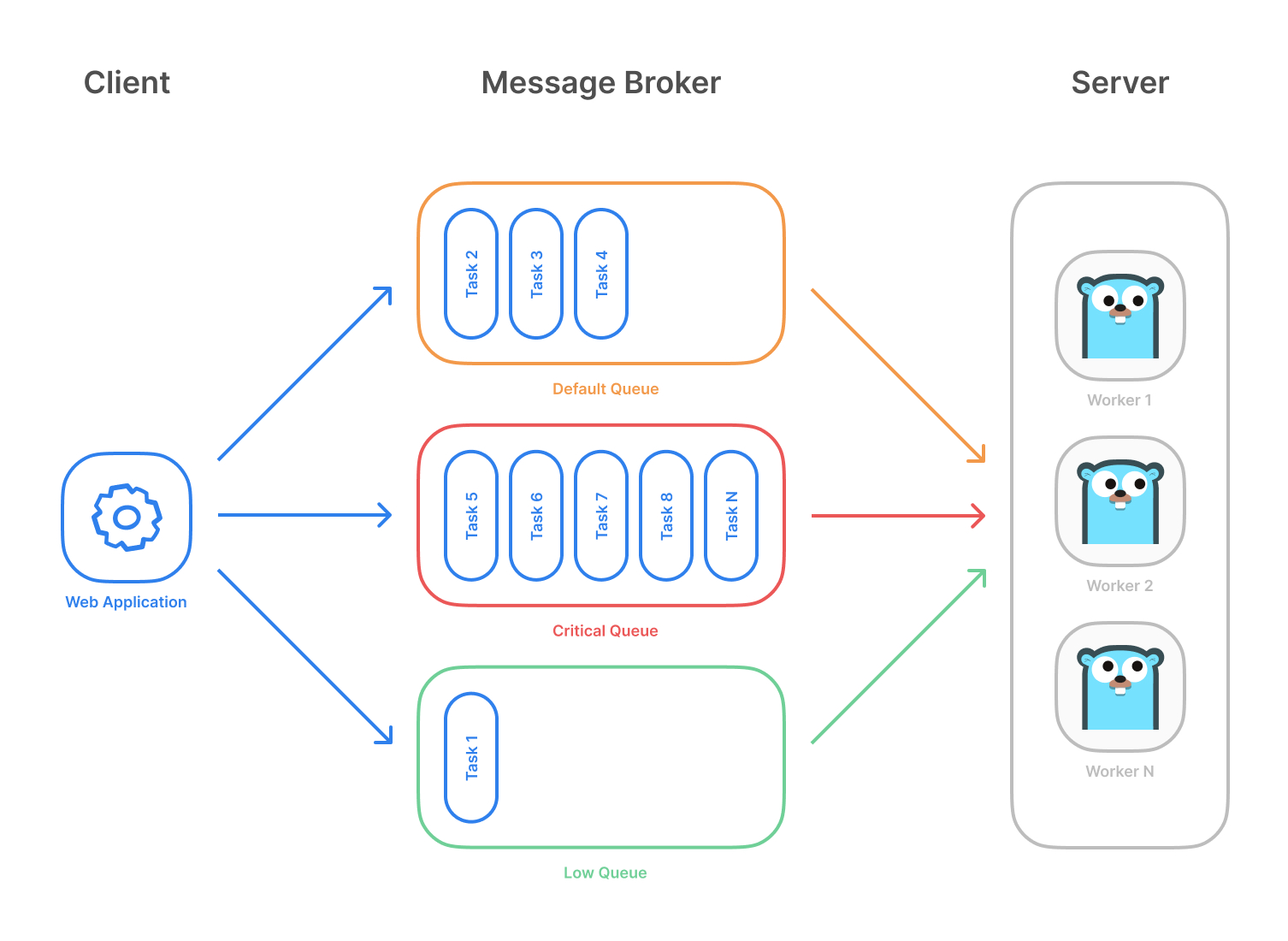
servicegroup
假如项目中需要使用多个消息队列(延时队列、定时队列),我们就需要对其进行服务管理,在go-zero里,提供了一个ServiceGroup工具,方便管理多个服务的启动和停止。
servicegroup的源码短小精悍,并且go-zero框架本身对每个服务(Restful, RPC, MQ)也基本都是通过ServiceGroup来管理。要使用servicegroup只需实现start和stop两个方法,就可以加入到serviceGroup统一管理。
kq已经实现了start和stop接口,这里用于实现第三方支付订单支付状态更新的消息队列,此处为消费者的实现,从kafka特定topic中取出第三方支付消息进行消费,并修改订单支付状态。
func (q *kafkaQueue) Start() { q.startConsumers() q.startProducers()
q.producerRoutines.Wait() close(q.channel) q.consumerRoutines.Wait()}
func (q *kafkaQueue) Stop() { q.consumer.Close() logx.Close()}package service
import ( "github.com/zeromicro/go-zero/core/logx" "github.com/zeromicro/go-zero/core/proc" "github.com/zeromicro/go-zero/core/syncx" "github.com/zeromicro/go-zero/core/threading")
type ( // Starter is the interface wraps the Start method. Starter interface { Start() }
// Stopper is the interface wraps the Stop method. Stopper interface { Stop() }
// Service is the interface that groups Start and Stop methods. Service interface { Starter Stopper }
// A ServiceGroup is a group of services. // Attention: the starting order of the added services is not guaranteed. ServiceGroup struct { services []Service stopOnce func() })
// NewServiceGroup returns a ServiceGroup.func NewServiceGroup() *ServiceGroup { sg := new(ServiceGroup) sg.stopOnce = syncx.Once(sg.doStop) return sg}
// Add adds service into sg.func (sg *ServiceGroup) Add(service Service) { // push front, stop with reverse order. sg.services = append([]Service{service}, sg.services...)}
// Start starts the ServiceGroup.// There should not be any logic code after calling this method, because this method is a blocking one.// Also, quitting this method will close the logx output.func (sg *ServiceGroup) Start() { proc.AddShutdownListener(func() { logx.Info("Shutting down services in group") sg.stopOnce() })
sg.doStart()}
// Stop stops the ServiceGroup.func (sg *ServiceGroup) Stop() { sg.stopOnce()}
func (sg *ServiceGroup) doStart() { routineGroup := threading.NewRoutineGroup()
for i := range sg.services { service := sg.services[i] routineGroup.Run(func() { service.Start() }) }
routineGroup.Wait()}
func (sg *ServiceGroup) doStop() { for _, service := range sg.services { service.Stop() }}
// WithStart wraps a start func as a Service.func WithStart(start func()) Service { return startOnlyService{ start: start, }}
// WithStarter wraps a Starter as a Service.func WithStarter(start Starter) Service { return starterOnlyService{ Starter: start, }}
type ( stopper struct{}
startOnlyService struct { start func() stopper }
starterOnlyService struct { Starter stopper })
func (s stopper) Stop() {}
func (s startOnlyService) Start() { s.start()}servicegroup对不同的服务进行管理和启动本质也是通过waitGroup实现。
func (g *RoutineGroup) Run(fn func()) { g.waitGroup.Add(1)
go func() { defer g.waitGroup.Done() fn() }()}函数在一个独立的Goroutine中运行,而waitGroup则可以用来等待Goroutine执行完毕。
go-zero并未像api和rpc一样提供对servicegroup的代码生成,项目通过模仿api/rpc目录结构进行改造(参考的官方用例)。
listen目录用于初始化和监听不同的消费队列消费者mqs目录用于管理不同的消息队列服务逻辑main.go用于将消费队列加入servicegroup,并启动消费者进行消费
main.go代码比较简单,包括初始化配置和服务,将消费队列加入servicegroup,并启动消费者进行消费。区别于api/rpc生成的main代码中使用mustnewserver方法来初始化配置,这里通过setup来初始。
package main
import ( "flag"
"microservices-go-zero/app/order/cmd/mq/internal/config" "microservices-go-zero/app/order/cmd/mq/internal/listen"
"github.com/zeromicro/go-zero/core/conf" "github.com/zeromicro/go-zero/core/service")
var configFile = flag.String("f", "etc/order.yaml", "Specify the config file")
func main() { flag.Parse() var c config.Config conf.MustLoad(*configFile, &c)
// init log、prometheus、trace、metricsUrl. if err := c.SetUp(); err != nil { panic(err) }
serviceGroup := service.NewServiceGroup() defer serviceGroup.Stop() for _, mq := range listen.Mqs(c) { serviceGroup.Add(mq) } // Start is a blocking function serviceGroup.Start()}其它的一些中间件的使用
Filebeat
Filebeat是Elastic Stack的一部分,主要用于轻量级日志采集器。它可以将日志或文件数据发送到Elasticsearch或Logstash,然后再进行分析和存储。本项目中,Filebeat从Docker容器中收集日志,并将这些日志发送到Kafka。我们在docker-compose-env.yaml文件中的filebeat部分将该配置文件挂载至filebeat容器的/usr/share/filebeat/filebeat.yml路径进行应用,并且将主机的/var/lib/docker/containers路径挂载到filebeat容器的相同路径,使其能读取所有主机所有容器的日志,并发送至kafka中。
output.kafka: enabled: true hosts: ["kafka:9092"] topic: "microservices-log" partition.hash: reachable_only: true compression: gzip max_message_bytes: 1000000 required_acks: 1enabled: true:启用Kafka输出。hosts: ["kafka:9092"]:Kafka服务器的地址和端口。topic: "microservices-log":指定Kafka主题名称,Filebeat将日志数据发送到这个主题。partition.hash.reachable_only: true:确保只将消息发送到可达的分区。compression: gzip:启用gzip压缩,减少网络传输数据量。max_message_bytes: 1000000:设置Kafka消息的最大字节数。required_acks: 1:设置Kafka生产者需要从服务器接收的确认数量,1表示至少要从一个服务器得到消息接收的确认。
Go-stash
go-stash属于go-zero生态的一个组件,是一个高效的从Kafka获取,根据配置的规则进行处理,然后发送到ElasticSearch集群的工具。 go-stash有大概logstash五倍的吞吐性能,并且部署简单,一个可执行文件即可。本项目中,go-stash中kafka中收集日志,进行处理过滤后(本项目移除了一些无用的、冗余的条目和字段,比如容器自己的信息;此外还对日志条目添加了inex,便于检索)发送至ElasticSearch集群中。我们在docker-compose-env.yaml文件中的go-stash部分将该配置文件挂载至go-stash容器的/app/etc/config.yml路径进行应用。
Prometheus
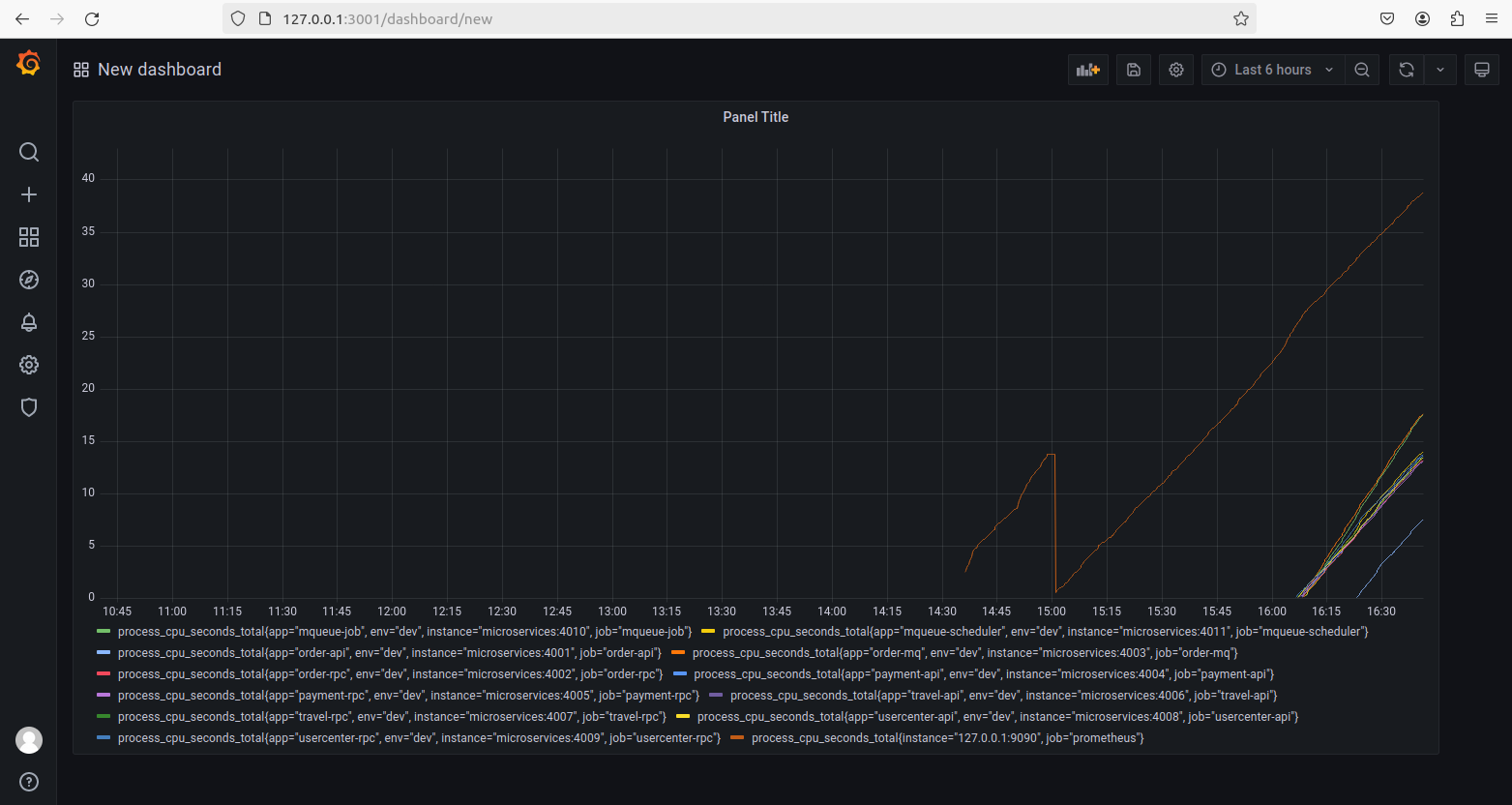
Prometheus是最初在SoundCloud上构建的开源系统监控和警报工具,在2016年加入了Cloud Native Computing Foundation(CNCF)基金会,是继Kubernetes之后该基金会的第二个托管项目。项目通过使用Promethues来监控压力测试时服务端的性能。
我们在docker-compose-env.yaml文件中的prometheus部分将该配置文件挂载至prometheus容器的/etc/prometheus/prometheus.yml路径进行应用,并且将容器中/prometheus路径中的内容持久化到/data/prometheus/data。每15秒从配置的目标中抓取一次指标数据。
本项目中主要监控的服务包括:
prometheus:127.0.0.1:9090order-api:microservices:4001order-rpc:microservices:4002order-mq:microservices:4003payment-api:microservices:4004payment-rpc:microservices:4005travel-api:microservices:4006travel-rpc:microservices:4007usercenter-api:microservices:4008usercenter-rpc:microservices:4009mqueue-job:microservices:4010mqueue-scheduler:microservices:4011
本项目中我们使用grafana查看Prometheus抓取的系统性能监控数据。
Elasticsearch
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建,用于全文搜索、结构化搜索和分析。它能够处理大规模的数据,提供实时的搜索和分析功能。
本项目使用kibana查看日志
Jaeger
Jaeger 是一个开源的分布式追踪系统,用于监控和故障排查微服务架构。它帮助开发者和运维人员了解和优化复杂分布式系统的性能。
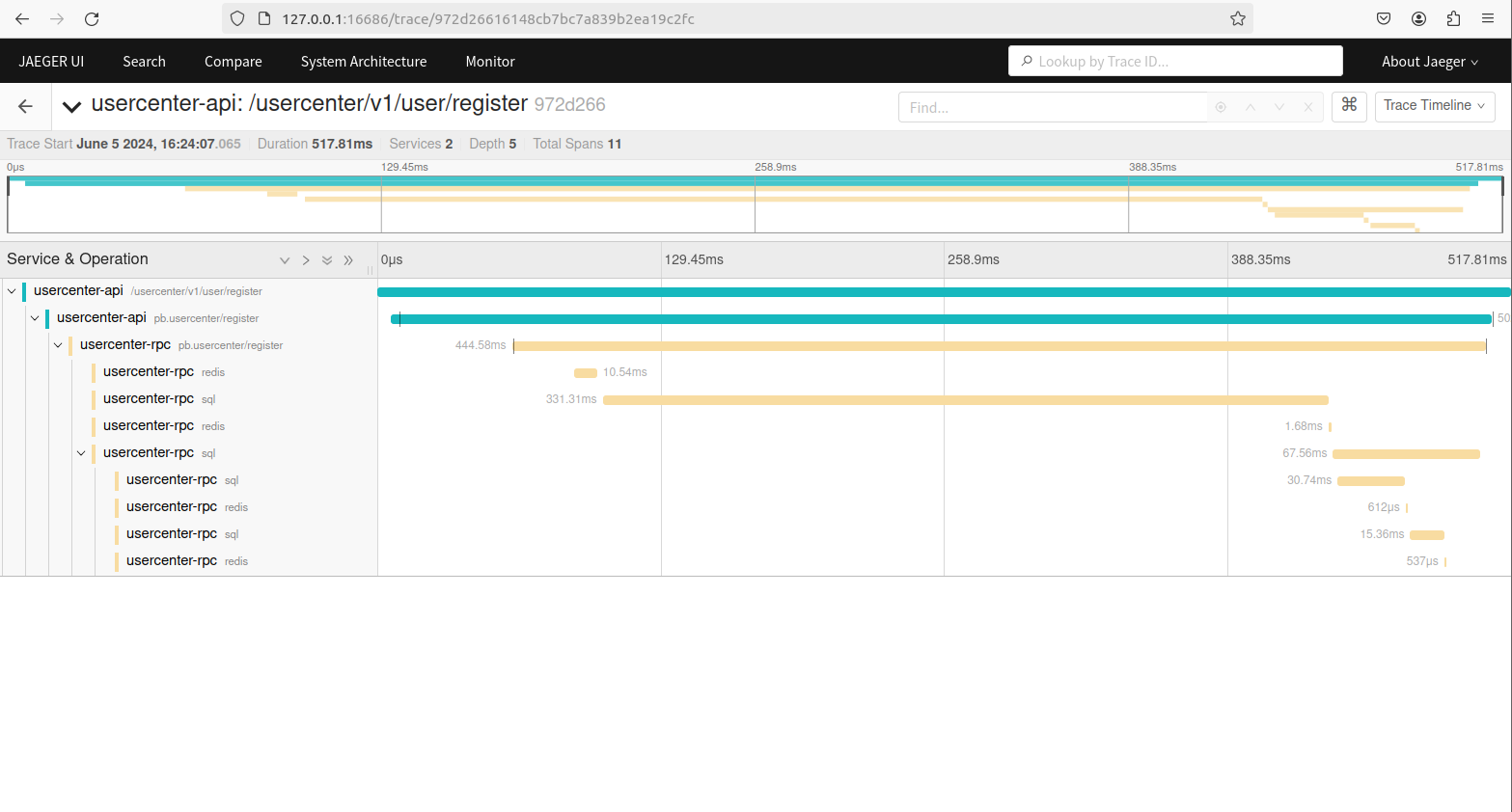
压力测试
使用Apache-Jmeter 5.6.3简单做了一下压力测试,只测试了一个接口。关于高性能,得辩证的去看待,脱离业务、机器和请求量,都是耍流氓。
测试环境
测试工具:Apache-Jmeter 5.6.3
系统环境
系统负载
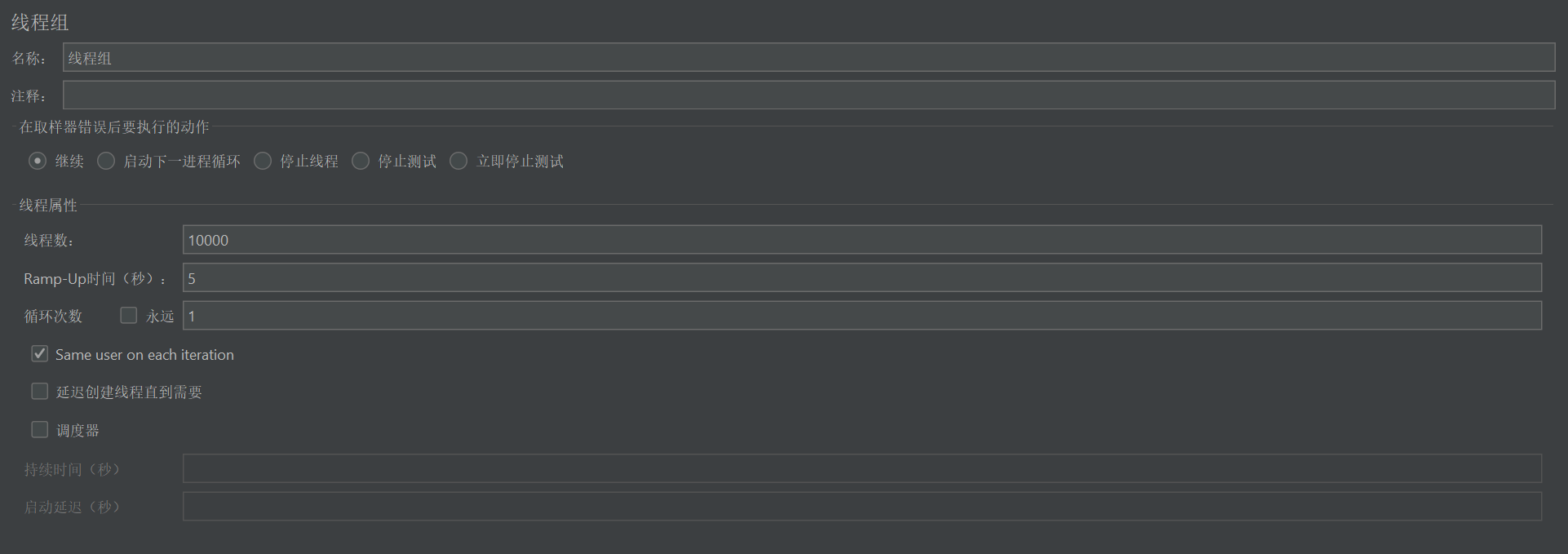
测试配置
模拟5s内1w个用户请求民宿推荐页面。
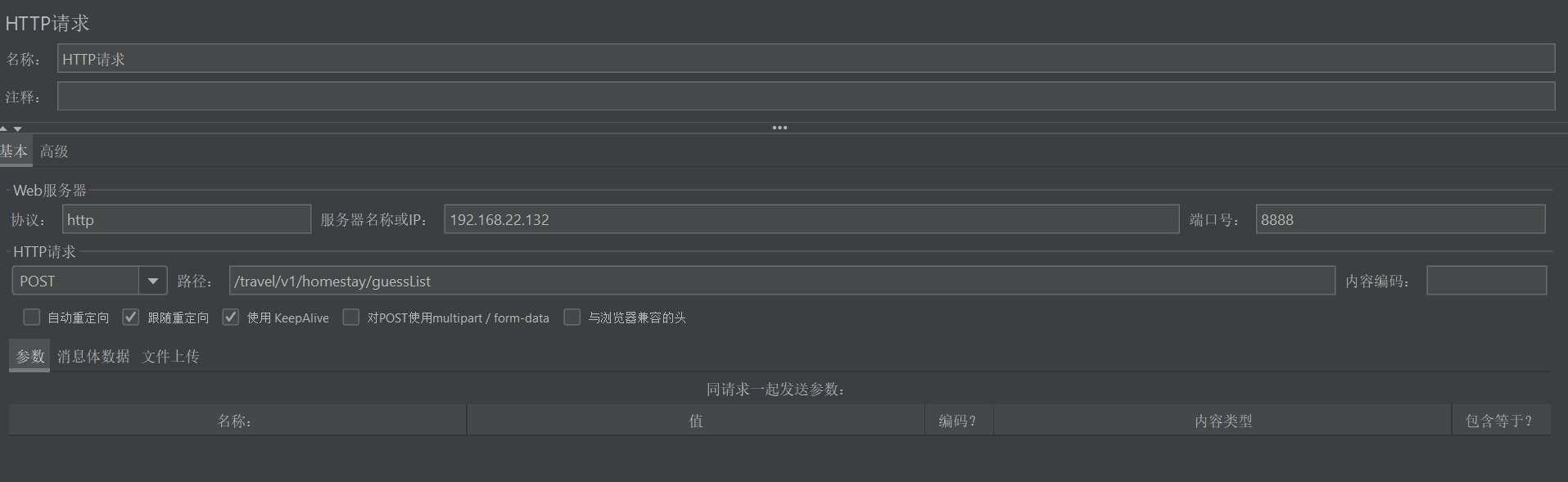

测试结果
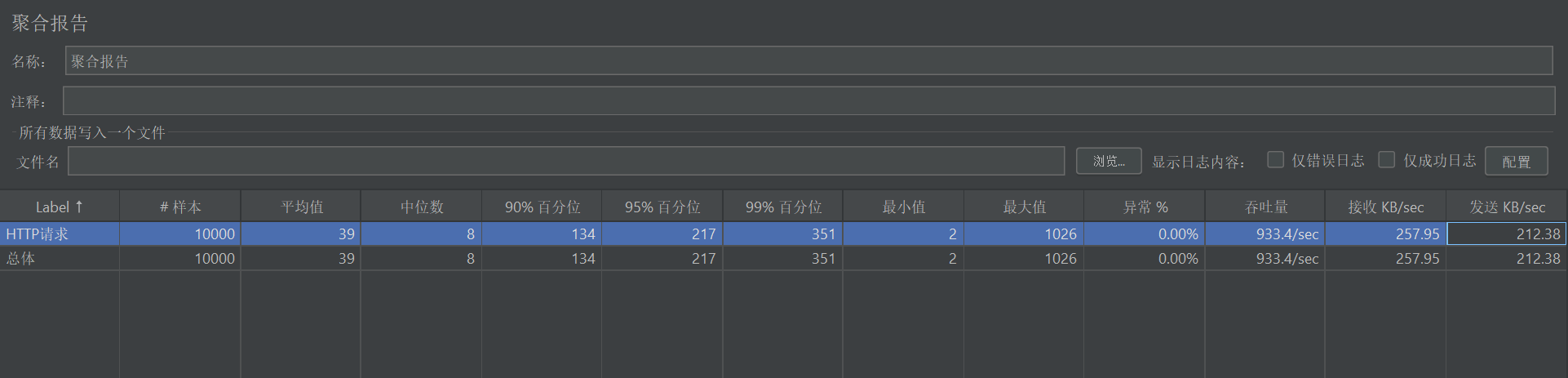
结果分析
响应时间
- 样本数:
10000 - 平均响应时间:
39 ms,说明大部分请求的响应时间较快。 - 中位数(50%响应时间):
8 ms,意味着一半的请求响应时间低于8 ms。 - 90%响应时间:
134 ms,说明绝大多数请求的响应时间在这个范围内。 - 95%响应时间:
217 ms,说明绝大多数请求的响应时间在这个范围内。 - 99%响应时间:
351 ms - 最小响应时间:
2 ms - 最大响应时间:
1026 ms,表明存在少量请求的响应时间较长,可能是由于服务器端的性能瓶颈(内存)。
吞吐量
- 吞吐量:
933.358 requests/sec,表明系统每秒可以处理约933个请求。 - 接收KB/sec:
257.949 KB/sec,数据传输速率也较高,表明系统在处理请求时的网络性能良好。 - 发送KB/sec:
212.375 KB/sec,数据传输速率也较高,表明系统在处理请求时的网络性能良好。 - 每分钟吞吐量:
56,001.493 requests/min,进一步验证了系统的高处理能力。
错误率
- 异常%:
0.0%,说明在测试期间所有请求都成功,没有发生错误。这是一个非常好的指标,表明系统在高负载下仍然稳定。
TPS(Transactions Per Second)
- TPS:
933.358 transactions/sec,TPS与吞吐量一致,表明每秒处理的事务数为933.358。
QPS(Queries Per Second)
- QPS:
933.358 queries/sec,QPS同样与吞吐量一致,表明每秒处理的查询数为933.358。
总结
- 响应时间: 整体响应时间较短,绝大多数请求的响应时间在合理范围内,但存在少量长响应时间的请求,大概率是因为系统硬件瓶颈。
- 吞吐量: 系统具有很高的吞吐量,能够处理大量并发请求。
- 错误率: 无错误请求,系统稳定性良好。
- TPS/QPS: 系统每秒处理的事务和查询数较高,性能表现出色。